Improving Audio Quality with Studio Sound
Studio Sound is Vocal Video's AI-powered audio cleanup. When it's on, it reduces background room noise, enhances voice clarity, and evens out volume levels — so your speakers sound polished and professional without any manual audio work.
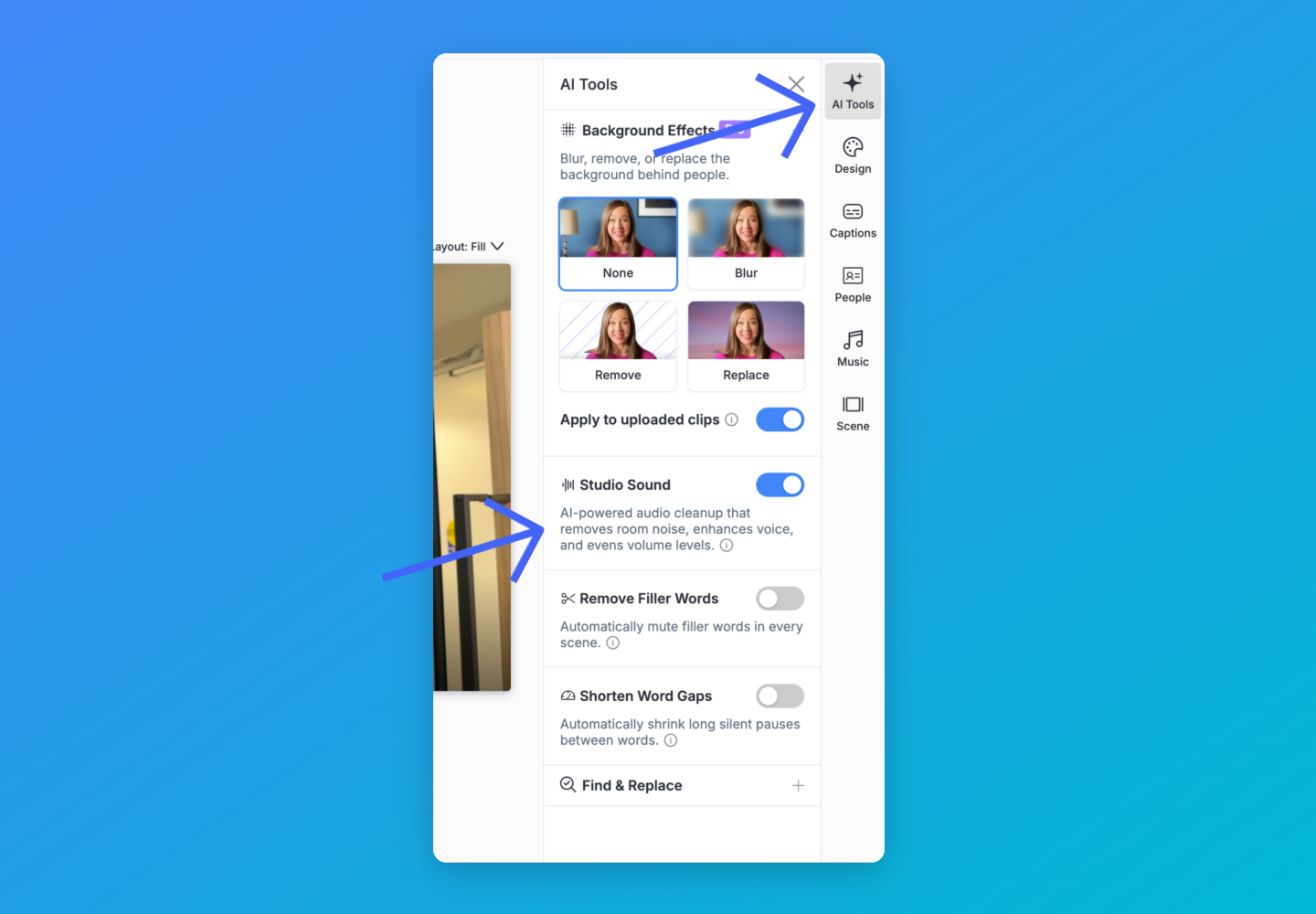
Turning Studio Sound on or off
Open a video in the Vocal Video editor and find the AI Tools panel in the right-hand sidebar. Studio Sound is the toggle there labeled "AI-powered audio cleanup." It's on by default for new videos.
Preview while you edit
You can hear Studio Sound while you edit — toggle it on and off to compare. When you publish, it's applied again at the highest quality on our render servers, so your published video sounds even better than the editor preview.
What Studio Sound does
- Reduces background noise — quiets room hum and ambient noise behind the speaker.
- Enhances voice clarity — shapes the audio so speech sounds warmer and more present.
- Evens out volume — automatically balances the loud and quiet moments, and levels volume between your different speakers and scenes, so everyone is easy to hear throughout your video.
Because Studio Sound balances volume for you, there's no need to manually adjust the volume of individual clips — leave your scenes at 100% and let Studio Sound do the work.
Studio Sound and AI credits
Studio Sound is an AI feature, so publishing a video with Studio Sound enabled uses AI credits. If you'd rather not use credits on a particular video, you can turn Studio Sound off for that video in the AI Tools panel before publishing.
Fine-tuning your audio
To adjust your music volume or the volume of an individual scene, see How to Adjust Audio Settings.